

Treat Skills as Code
Agent skills are the most portable tool in agentic engineering. Time to give them the quality discipline they deserve.

Agent skills have quietly become the most portable building block in agentic engineering. A single SKILL.md file works across Claude Code, Gemini CLI, Codex, and any agent that supports the open standard. Write it once, use it everywhere. No vendor lock-in, no framework dependency, no API integration. Just a folder with markdown and optional scripts.
That portability is why skills matter more than most people realize. MCPs tie you to specific tool integrations. Custom agents require scaffolding. Skills are plain text that any model can read, and they carry your team’s institutional knowledge in a format that survives platform changes.
But there’s a problem. We treat skills like documentation when we should treat them like code.
Skills Ship Without Tests
Every other dependency in your stack has quality gates. Libraries have test suites. APIs have contracts. Infrastructure has validation. Skills have none of that. They’re markdown files that load into a context window and steer agent behavior with zero guarantees.
A broken skill doesn’t throw an error. It silently degrades output, triggers on the wrong task, or wastes tokens explaining things the model already knows. You won’t see a stack trace. You’ll see a slightly worse result that you might not even notice, because you have no baseline to compare against.
Most skill authors iterate by feel. Write the SKILL.md, test it manually a couple of times, ship it, move on. Did it actually trigger when it should? No idea. Did it improve output quality? Probably, maybe, it felt better. When models update (and they update constantly), did the skill stop working? You’ll find out when someone complains, or more likely, you won’t find out at all.
This is the measurement gap. Without a baseline, you can’t distinguish a skill that helps from one that wastes tokens. Without regression testing, model updates silently break skills that worked last month. Without structured evaluation, “it seems better” is the best feedback you’ll ever get. Improving from anecdotal evidence is like optimizing database queries without a profiler.
The skills ecosystem keeps growing. The Tessl Registry hosts over 2,000 public skills. Teams are building internal skill libraries shared across engineering organizations. Multiple agents consuming the same broken skill compounds the damage across every session. Anthropic acknowledged the gap directly in their March 2026 skill-creator update, which added structured evals and benchmarking to the authoring workflow. The ecosystem needed quality infrastructure. It’s arriving.
What Makes a Skill Good
Before reaching for evaluation tools, you need to know what “good” looks like. These heuristics come from Anthropic’s best practices, Tessl’s review scoring criteria, and findings from the SkillsBench benchmark. They catch the majority of issues manually.
Trigger accurately
The description field in your frontmatter is the only thing the agent reads before deciding whether to load the full skill. It carries disproportionate weight.
# Good: specific, third-person, includes trigger phrases
---
name: api-design
description: >
Designs REST APIs following team conventions for naming,
versioning, and error handling. Use when creating new
endpoints, reviewing API designs, or updating existing
APIs to match current standards.
---
# Bad: vague, no trigger context
---
name: api-helper
description: Helps with API stuff
---Write descriptions in third person. Include an explicit “Use when...” clause. Test the description against near-miss queries, things that share keywords with your skill but shouldn’t trigger it. The negative test cases matter more than the positive ones. Anthropic’s documentation notes that Claude uses the description to choose the right skill from potentially 100+ available skills. If your description doesn’t include both what the skill does and when to use it, the skill is invisible.
Stay lean
Every token in your SKILL.md competes with conversation history, other skills, and the actual task. Anthropic’s guidance is blunt: Claude is already very smart. Only add context Claude doesn’t have.
The single highest-leverage improvement for any skill: read every paragraph and ask, “If I delete this, would the agent’s output actually get worse?” If the answer is probably not, delete it. Most skills are 40-60% longer than they need to be. Don’t explain what PDFs are before showing how to extract text from them. Don’t define REST conventions before describing your team’s specific API patterns. Encode what’s unique to your context: team conventions, architecture decisions, deployment procedures.
Keep SKILL.md under 500 lines. Under 300 is better.
Use progressive disclosure
Skills use a three-level loading system that controls token cost. At startup, only metadata (name and description, roughly 100 tokens) loads into context. The full SKILL.md loads only when the skill triggers. Referenced files load only when the SKILL.md explicitly directs the agent to read them.
api-design/
├── SKILL.md ← Loads on trigger (~200 lines)
├── references/
│ ├── error-codes.md ← Loads only when needed
│ └── naming-rules.md ← Loads only when needed
└── scripts/
└── validate.py ← Executes, never loads into contextPut detailed schemas, checklists, and examples in reference files. Never chain references more than one level deep. SKILL.md can point to references/error-codes.md, but that file should not reference another file. Agents fail on multi-hop chains.
Match specificity to the need
Not every instruction needs the same specificity. Match it to how fragile the task is.
Database migrations need exact scripts with no parameters. This requires high specificity, because variation is a bug. Code review needs heuristics and guidance, because the right feedback depends on context. Report generation sits in the middle: provide a template but let the agent adapt to the data.
For every instruction that uses MUST, ALWAYS, or NEVER, check whether you’ve explained why. “Filter test accounts because production reports with test data caused incorrect business decisions” works better than “ALWAYS filter test accounts.” Models respond to reasoning better than commands.
Make it testable
A skill you can’t evaluate is a skill you can’t improve. Design with verification in mind. Identify the failure modes you’d see without the skill. Define what correct output looks like for 3-5 realistic scenarios. Include concrete input/output examples in the skill itself, because models follow demonstrated patterns better than abstract instructions.
# In your eval definition
{
"skill_name": "api-design",
"evals": [
{
"id": 1,
"prompt": "Design endpoints for user profile management",
"expected_output": "REST endpoints following team naming
conventions with proper versioning and error handling",
"assertions": [
"Uses plural nouns for resource names",
"Includes /v1/ path prefix",
"Defines error response schema"
]
}
]
}These heuristics work for manual review. But manual review doesn’t scale, doesn’t catch regressions across model updates, and doesn’t produce the data you need to improve systematically. That requires tooling.
The Evaluation Landscape
At least three solutions now exist for skill evaluation. Each approaches the problem from a different angle, and together they signal where the market is heading: skills require the same quality infrastructure as any other code dependency.
Anthropic Skill-Creator 2.0
Anthropic’s March 2026 update added structured evaluation directly into the skill authoring workflow. It runs parallel A/B tests with blind comparison (a comparator agent judges output quality without knowing which version produced it). It optimizes trigger descriptions using a train/holdout split to prevent overfitting. The entire workflow runs through natural language. No coding required.
The limitation is scope. Skill-creator works inside Claude’s ecosystem only. No cross-model testing, no CI/CD integration, no registry for distributing evaluated skills to a team.
Promptfoo (OpenAI)
OpenAI acquired Promptfoo on March 9, 2026 for its evaluation and red-teaming capabilities. Promptfoo’s open-source CLI lets you define test rubrics in YAML, run assertions against agent output, and scan for security vulnerabilities using OWASP and NIST presets. Over 350,000 developers use it, including teams at 25% of Fortune 500 companies.
Promptfoo is a general-purpose eval tool, not skill-specific. It has no structural review, no skill registry, and no built-in concept of baseline-vs-skill comparison. OpenAI committed to keeping it open source, but the deepest integration will favor the Frontier enterprise platform. It represents where OpenAI sees the evaluation layer heading: embedded in the platform, tightly coupled with agent deployment.
Tessl
Tessl is the most vendor-agnostic option available at the moment. Built as a package manager for agent skills, it provides the full lifecycle: build, evaluate, distribute, optimize. Its evaluation stack has three layers.
tessl skill lint validates structure and packaging. Does the frontmatter parse? Are required fields present? Think of it as a compilation check.
tessl skill review scores your skill against best practices across three dimensions: validation (schema hygiene), implementation quality (clear instructions, concrete examples), and activation quality (discoverable triggers, specific keywords). The output includes actionable suggestions.
$ tessl skill review ./api-design
Validation Checks
✔ frontmatter_valid
✔ name_field - 'api-design'
✔ description_field - valid (186 chars)
✔ description_voice - uses third person
⚠ description_trigger_hint - missing 'Use when...'
✔ skill_md_line_count - 147 (<= 500)
Implementation Score: 78%
Activation Score: 62%
Overall Score: 71%tessl eval run measures behavioral impact. It generates realistic scenarios, runs the agent through each scenario with and without the skill, and scores outputs against criteria. The gap between baseline and skill-augmented scores tells you whether the skill changes behavior in the direction you want. If there’s barely any difference, the agent handled the task fine without your skill. If scores drop, the instructions hurt more than they help.
Tessl’s registry hosts over 2,000 evaluated skills. Evals run automatically when you publish, catching regressions before they reach users. Results are version-pinned, so you can compare v1.1.0 against v1.2.0 with data instead of intuition. It works across Claude Code, Gemini CLI, Codex, and any agent supporting the skill spec.
Where each tool fits
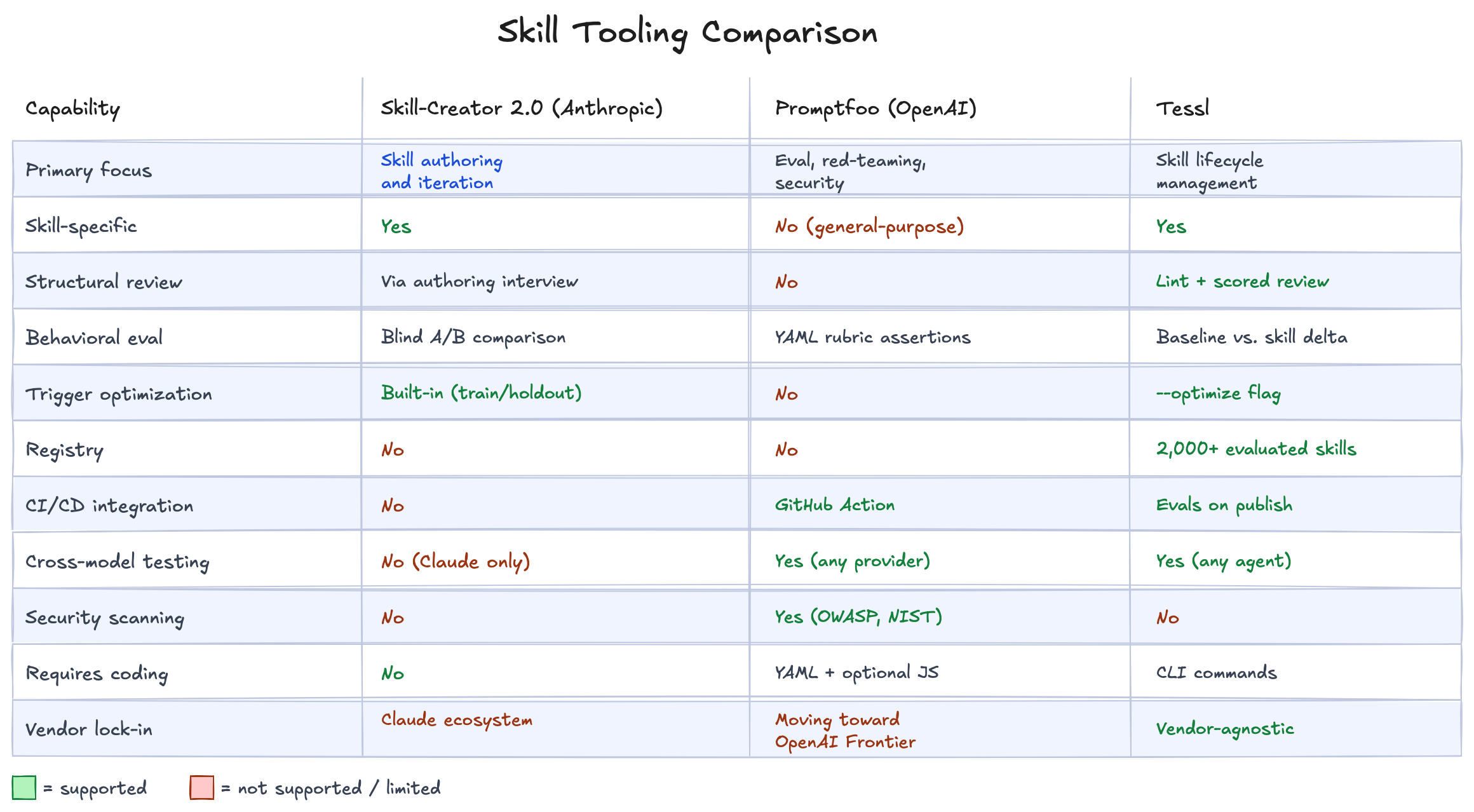
These tools aren’t competing. They’re complementary, and together they represent the market converging on a single idea: skills need quality infrastructure. Anthropic built it into the authoring experience. OpenAI acquired it for the security layer. Tessl built the vendor-agnostic lifecycle platform.
The practical starting point: use Anthropic’s skill-creator for the authoring loop if you’re working in Claude. Use Tessl’s lint and review to catch structural issues and get a scored quality baseline that works across agents. The tools compose well together, and Tessl’s own documentation suggests using both.
What This Means
Skills are the most portable, most universal tool available for specializing AI agents. They work across models, across agents, across platforms. That’s rare in an ecosystem where most tools lock you into a specific vendor.
But portability without quality is just distributing problems faster. A bad skill deployed across a team’s agents doesn’t fail loudly. It fails quietly, across every session, degrading output in ways nobody measures because nobody has a baseline.
The evaluation infrastructure now exists. Anthropic, OpenAI, and Tessl each built their version in the first quarter of 2026. The question isn’t whether the tooling is ready. The question is whether we’ll apply the same discipline to skills that we apply to every other dependency in our stack.
What does your team’s skill quality process look like? Are you measuring impact, or still iterating by feel?